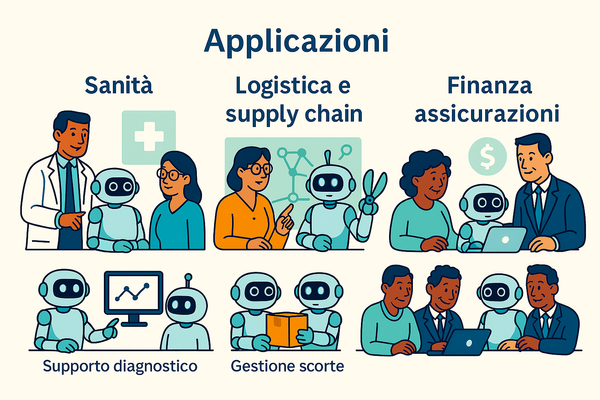
Impatto Computazionale ed Energetico


📄 Questo articolo è un estratto del documento completo
“Agenti AI: Prospettive, Sfide e Architetture per un Futuro Inclusivo e Sostenibile”, che puoi leggere e scaricare liberamente in fondo alla pagina.
✉️ Se ti va, registrati gratuitamente: così potremo rimanere in contatto e aggiornarti su nuovi contenuti e iniziative!
L’altro lato della medaglia
L’adozione di Agenti AI implica sempre di più l’uso di modelli di linguaggio di grandi dimensioni (LLM), con un costo computazionale ed energetico non trascurabile. Se da un lato questi modelli consentono livelli di comprensione e automazione mai visti prima, dall’altro rischiano di generare costi elevati e un’impronta carbonica significativa se non si adottano tecniche di ottimizzazione mirate.
Costi e consumi di GPU/TPU
- Hardware specializzato. Per eseguire LLM di punta (es. GPT-4, Claude, ecc.) servono GPU/TPU che possono costare svariate migliaia di euro l’una. Un singolo server può montare sino 8 di queste schede, con costi che aumentano rapidamente in caso di progetti su larga scala.
- Energia e raffreddamento. Le GPU di fascia alta richiedono diversi kW di potenza per funzionare, a cui si somma il dispendio energetico necessario per dissipare il calore prodotto. Di conseguenza, l’impatto ambientale e i costi in bolletta possono diventare rilevanti, specialmente per sistemi che operano 24/7.
- Noleggio in cloud. I principali fornitori (AWS, Azure, Google) permettono di “affittare” istanze GPU/TPU a tariffe orarie, che possono oscillare tra i 2 e i 5 €/ora per singola GPU. Per progetti di ricerca o scenari operativi h24, i costi mensili possono arrivare a diverse migliaia di euro.
- Trade-off: investire in hardware on-premise (costi iniziali e manutenzione) vs. la maggiore flessibilità del cloud.
Strategie di ottimizzazione
Fortunatamente, esistono tecniche per ridurre il costo e il consumo energetico, mantenendo prestazioni vicine ai modelli completi:
- Quantizzazione:
- Consiste nel “ridurre” la precisione numerica (es. da 16 bit a 8 bit).Il modello diventa più leggero da calcolare, con un lieve calo di accuratezza (spesso trascurabile).
- Risultato: meno RAM/VRAM occupata, minor carico computazionale.
- Pruning
- Si “potano” i neuroni o i pesi meno rilevanti, mantenendo in vita solo le parti più informative del modello.
- Ciò diminuisce il numero di operazioni necessarie durante l’inferenza, tagliando drasticamente consumi e latenza.
- Distillazione dei modelli
- Un modello più piccolo (“studente”) impara a replicare le risposte di uno più grande (“insegnante”). Spesso, il modello distillato conserva buona parte delle performance del “maestro”, ma con una dimensione e un costo computazionale nettamente inferiori.
- Esempi: DistilBERT, DistilGPT2.
L’importanza della sostenibilità
Oltre a ridurre i costi operativi, queste tecniche contribuiscono a un uso più etico e responsabile dell’IA, specialmente in un momento storico in cui la green transition è un imperativo per molte aziende.
Edge computing: integrare modelli ottimizzati anche su dispositivi locali (smartphone, gateway industriali) riduce la dipendenza dal cloud e il traffico di rete.
Energia rinnovabile: alcuni data center e aziende scelgono di alimentare i propri sistemi con fonti green, mitigando ulteriormente l’impatto ambientale.
Conclusioni
Il “potere” degli Agenti AI ha un costo, in termini di risorse hardware e consumi energetici. Conoscere e applicare strategie di ottimizzazione (quantizzazione, pruning, distillazione) è essenziale per bilanciare innovazione e sostenibilità, evitando di trovarsi con spese e impatti fuori controllo.
Nel prossimo articolo parleremo di Opportunità, Prospettive Future e Implicazioni Socio-Economiche: in che modo gli Agenti AI influenzeranno il mercato del lavoro e l’ecosistema industriale?
Nel frattempo, puoi approfondire l’argomento scaricando qui il PDF completo.