Le Origini del Machine Learning: Dalle Visioni dei Pionieri alle Applicazioni Moderne


Alla base di strumenti come assistenti vocali, auto a guida autonoma e diagnostica medica avanzata, il ML consente alle macchine di apprendere dai dati senza essere esplicitamente programmate. Ma come è iniziato tutto questo?
Questo articolo ripercorre le tappe fondamentali del machine learning, dalle intuizioni pionieristiche di Alan Turing agli sviluppi moderni del deep learning, esplorando contributi chiave di figure come Walter Pitts, Warren McCulloch, Frank Rosenblatt, John Hopfield e Geoffrey Hinton. Inoltre, analizzeremo le sfide attuali del ML, come la scalabilità dei modelli, e introdurremo i concetti emergenti di agente e agente autonomo, che stanno ridefinendo il futuro dell’intelligenza artificiale.
1. Le Prime Radici: Alan Turing e la Nascita dell’Intelligenza delle Macchine

La storia del machine learning inizia con Alan Turing, uno dei padri dell'informatica moderna. Nel 1950, Turing pubblicò il celebre articolo Computing Machinery and Intelligence, in cui introdusse il famoso Test di Turing per valutare l'intelligenza artificiale. L'idea era semplice ma potente: se una macchina riesce a simulare una conversazione umana in modo indistinguibile, allora può essere considerata "intelligente".
Punti chiave del contributo di Turing:
- La Macchina di Turing: Un modello teorico di calcolatore universale che formalizzava il concetto di computazione.
- Il Test di Turing: Una pietra miliare nel dibattito sull’intelligenza delle macchine, che ha ispirato la nascita dell’intelligenza artificiale e del machine learning.
Turing non sviluppò algoritmi specifici di ML, ma il suo lavoro fu fondamentale per gettare le basi teoriche del campo, aprendo la strada a studi futuri sull'apprendimento automatico.
2. Walter Pitts e Warren McCulloch: I Precursori delle Reti Neurali

Nel 1943, Walter Pitts, un giovane logico prodigio, e Warren McCulloch, neurofisiologo, pubblicarono A Logical Calculus of the Ideas Immanent in Nervous Activity. In questo lavoro visionario, introdussero il neurone artificiale McCulloch-Pitts, un modello matematico che simulava il comportamento dei neuroni biologici.
Contributi chiave:
- Reti Neurali Artificiali: Proposero il primo modello matematico che dimostrava come reti di neuroni interconnessi potessero eseguire calcoli logici complessi.
- Logica e Biologia: Dimostrarono che processi cognitivi potevano essere descritti con formule matematiche.
Nonostante la loro importanza, le reti di Pitts e McCulloch erano statiche e incapaci di apprendere, un limite che sarà superato successivamente con il lavoro di Rosenblatt.
3. Frank Rosenblatt e il Percettrone: La Prima Macchina che Impara

Nel 1957, Frank Rosenblatt sviluppò il percettrone, uno dei primi modelli computazionali in grado di apprendere dai dati. Ispirato alla struttura dei neuroni biologici, il percettrone poteva classificare dati semplici, come distinguere tra due tipi di forme geometriche.
Limiti e Impatto:
- Limitazioni: Il percettrone non riusciva a risolvere problemi non lineari, come la funzione XOR, un limite evidenziato da Marvin Minsky e Seymour Papert nel libro Perceptrons (1969).
- Eredità: Nonostante le critiche, il lavoro di Rosenblatt ispirò lo sviluppo di reti neurali multilivello, che sarebbero diventate fondamentali per il deep learning.
I Problemi Non Lineari: Una Definizione
Un problema è considerato non lineare quando la relazione tra le variabili di input e output non può essere rappresentata da una linea retta o un'equazione lineare.
Esempio di problema lineare:
Prevedere il prezzo di una casa in base alla superficie. Qui la relazione è lineare: all’aumentare della superficie, il prezzo aumenta proporzionalmente.
Esempio di problema non lineare:
Se il prezzo della casa dipende anche da altre caratteristiche, come la posizione o lo stato del mercato, la relazione diventa complessa e non lineare, richiedendo modelli più avanzati per essere risolta.
Nonostante il temporaneo declino di interesse nelle reti neurali dopo le critiche al percettrone, i contributi di John Hopfield e Geoffrey Hinton negli anni ’80 hanno rilanciato il campo.
4. Gli Anni '80: L’Avvento delle Reti Hopfield e della Retropropagazione
John Hopfield e le Reti per la Memoria Associativa

Le Reti Hopfield, introdotte nel 1982 da John Hopfield, rappresentano un approccio innovativo e specifico nel panorama delle reti neurali. Progettate per risolvere problemi di memoria associativa, queste reti sono in grado di memorizzare informazioni e recuperarle quando vengono fornite versioni parziali o corrotte.
Struttura e Funzionamento:
Le Reti Hopfield sono reti completamente connesse, dove ogni nodo rappresenta un neurone che comunica con tutti gli altri. Le connessioni sono definite da una matrice di pesi simmetrica, il che significa che il peso tra due neuroni è identico in entrambe le direzioni. Questo design crea un sistema che evolve verso stati stabili, corrispondenti a soluzioni memorizzate.
Le informazioni vengono immagazzinate come attrattori, ovvero stati stabili del sistema. Quando un input rumoroso o incompleto viene fornito, la rete converge verso l’attrattore più vicino, ricostruendo la versione completa dell’informazione. La convergenza è guidata da una funzione di energia minima, che assicura che il sistema raggiunga uno stato stabile e coerente con i dati memorizzati.
Esempio Pratico:
Immagina una Rete Hopfield che memorizza immagini in bianco e nero. Se viene fornita un'immagine parzialmente corrotta, la rete può correggere l'input, recuperando l'immagine completa grazie agli stati stabili precedentemente immagazzinati.
Limiti delle Reti Hopfield:
Nonostante la loro eleganza e applicabilità a compiti specifici, le Reti Hopfield presentano alcune limitazioni:
- Scalabilità Limitata: Il numero massimo di informazioni che possono essere memorizzate è proporzionale al numero di neuroni, rendendole inadatte per problemi su larga scala.
- Ambito Applicativo Ristretto: Funzionano bene per il riconoscimento di pattern e l’ottimizzazione, ma non sono adatte per la classificazione generale o compiti complessi.
- Non Linearità Limitata: Sebbene gestiscano relazioni non lineari attraverso attrattori multipli, la loro capacità di rappresentare relazioni complesse è limitata rispetto alle reti neurali profonde.
La Retropropagazione: La Svolta per le Reti Profonde
Negli anni ’80, Geoffrey Hinton, insieme a David Rumelhart e Ronald Williams, introdusse l’algoritmo di retropropagazione, che superò molte delle limitazioni delle Reti Hopfield e rese possibile l’addestramento di reti neurali multilivello (MLP).

Funzionamento e Caratteristiche:
- Strutture Multistrato:
Le reti profonde utilizzano strati nascosti che creano rappresentazioni intermedie degli input. Questi strati consentono di estrarre caratteristiche complesse e non lineari, difficilmente individuabili da modelli più semplici. - Funzioni di Attivazione Non Lineari:
Funzioni come la ReLU (Rectified Linear Unit) e la sigmoide introducono non linearità, consentendo di modellare relazioni intricate tra input e output. - Aggiornamento Iterativo dei Pesi:
La retropropagazione calcola l’errore in ogni strato e aggiorna i pesi iterativamente utilizzando il gradiente discendente, minimizzando l’errore complessivo del modello.
Esempio Pratico:
Considera una rete con retropropagazione che classifica immagini di animali. Se alcune caratteristiche tra cani e gatti si sovrappongono, la rete utilizza i suoi strati nascosti per creare rappresentazioni profonde e distinguere caratteristiche più sottili come la consistenza del pelo o la forma delle orecchie.
Confronto tra Reti Hopfield e Retropropagazione
Le Reti Hopfield e la Retropropagazione rappresentano approcci distinti e complementari per affrontare la non linearità.
| Caratteristica | Reti Hopfield | Retropropagazione |
|---|---|---|
| Tipo di Problema | Memoria associativa, ottimizzazione | Classificazione, regressione |
| Affrontare la Non Linearità | Attrattori multipli, convergenza stabile | Strati nascosti, funzioni di attivazione |
| Ambito Applicativo | Pattern recognition, ottimizzazione | Visione artificiale, linguaggio naturale |
| Scalabilità | Limitata a problemi piccoli | Altamente scalabile con GPU e TPU |
Le Reti Hopfield eccellono in problemi specifici, come il recupero di informazioni o il riconoscimento di pattern, grazie alla loro capacità di gestire relazioni non lineari in sistemi di dimensioni limitate. Tuttavia, il loro impatto è confinato a contesti specifici.
L’introduzione della retropropagazione, invece, ha ampliato drasticamente il panorama delle reti neurali, consentendo di affrontare una vasta gamma di problemi complessi e di grande scala. La combinazione di strati profondi, funzioni di attivazione non lineari e capacità di generalizzazione ha reso la retropropagazione una pietra miliare nel machine learning, gettando le basi per il deep learning e le sue applicazioni moderne.
Questi due approcci, pur avendo scopi e ambiti diversi, hanno contribuito in modo complementare a superare i limiti dei modelli lineari, ridefinendo ciò che è possibile con il machine learning.
5. L’Era dei Big Data e il Rilancio del Machine Learning
Con l’arrivo dei big data negli anni 2000, il machine learning ha vissuto una trasformazione radicale. La disponibilità di enormi dataset e i progressi hardware, come le GPU (Graphics Processing Units) e le TPU (Tensor Processing Units), hanno reso possibile l’addestramento di modelli complessi che affrontano problemi di scala e complessità crescenti. Questo cambiamento ha portato a innovazioni significative, come le reti neurali convoluzionali (CNN) e i modelli linguistici di grandi dimensioni (LLM, Large Language Models), che oggi sono alla base di molte delle applicazioni moderne dell’intelligenza artificiale.
Le CNN: Un’Evoluzione per la Visione Artificiale
Le reti convoluzionali (CNN) sono state progettate specificamente per lavorare con dati strutturati in griglie, come immagini. A differenza delle reti completamente connesse, che trattano ogni input come indipendente, le CNN sfruttano strati convoluzionali per analizzare piccole sezioni locali dei dati, riducendo drasticamente il numero di parametri e preservando le informazioni spaziali.
Applicazioni delle CNN:
- Riconoscimento facciale: Sistemi di sicurezza biometrica e applicazioni fotografiche.
- Segmentazione di immagini mediche: Rilevamento di tumori o altre anomalie in scansioni radiografiche e MRI.
- Generazione di immagini realistiche con GAN: Tecnologie generative utilizzate in creatività digitale, design e simulazioni.
Le CNN sono state il punto di svolta per il machine learning nei dati visivi, ma l'avvento degli LLM ha ampliato il campo anche ai dati descrittivi, trasformando il modo in cui l’intelligenza artificiale elabora e comprende il linguaggio naturale.
I LLM: Comprendere e Classificare il Linguaggio
Gli Large Language Models, come GPT (Generative Pre-trained Transformer) e BERT (Bidirectional Encoder Representations from Transformers), rappresentano un ulteriore progresso nel machine learning, sfruttando le enormi quantità di dati testuali disponibili sul web. Addestrati su dataset di molti miliardi di frasi, questi modelli non solo comprendono il linguaggio naturale, ma possono anche generare contenuti, rispondere a domande e classificare dati descrittivi in modo semantico.
Ruolo degli LLM nella Classificazione Semantica:
A differenza dei modelli tradizionali, che si basano su regole predefinite, gli LLM possono analizzare grandi quantità di dati descrittivi per identificarne il significato intrinseco. Ad esempio, possono:
- Classificare recensioni di prodotti: Determinando se il feedback è positivo, negativo o neutro.
- Estrarre entità chiave: Come nomi, date e luoghi, utili per l’analisi di grandi set di documenti.
- Segmentare contenuti in categorie semantiche: Utile in settori come l’e-commerce, dove descrizioni di prodotti devono essere organizzate in modo efficace.
LLM e Agenti Interattivi
L’interazione tra LLM e agenti autonomi ha aperto nuove possibilità nel campo degli agenti interattivi, che utilizzano il linguaggio naturale per interfacciarsi con gli utenti.
Esempi di utilizzo:
- Assistenti virtuali avanzati: Come ChatGPT, che comprende e risponde a domande complesse in linguaggio naturale.
- Automazione del customer service: Gli agenti virtuali possono rispondere a richieste comuni, classificare i problemi e trasferirli a specialisti se necessario.
- Supporto decisionale: Sistemi che analizzano grandi volumi di dati descrittivi e forniscono raccomandazioni basate sul contesto.
Gli LLM non solo potenziano gli agenti, ma ne migliorano anche la capacità di apprendere dinamicamente, adattandosi a nuovi scenari grazie alla loro comprensione semantica.
6. Le Sfide della Scalabilità e il Futuro del Machine Learning
Nonostante i progressi di CNN, LLM e agenti autonomi, il machine learning deve ancora affrontare alcune sfide critiche:
- Costo Computazionale: Addestrare modelli di grandi dimensioni richiede infrastrutture costose e dispendiose in termini energetici.
- Efficienza Energetica: L’impatto ambientale dei modelli avanzati è significativo, spingendo verso soluzioni più sostenibili.
- Disponibilità dei Dati: Le applicazioni specifiche richiedono dataset di alta qualità, spesso difficili da ottenere o etichettare.
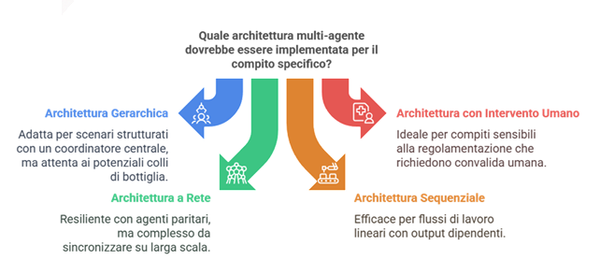
Gli Agenti e agli Agenti Autonomi
Un approccio emergente per affrontare queste sfide è rappresentato dagli agenti e dagli agenti autonomi.
Agenti:
Entità software o hardware che percepiscono l’ambiente, analizzano i dati e agiscono in base a un obiettivo prefissato.
Agenti Autonomi:
Questi sistemi avanzati possono prendere decisioni complesse senza intervento umano, adattandosi dinamicamente a nuovi scenari. Ad esempio:
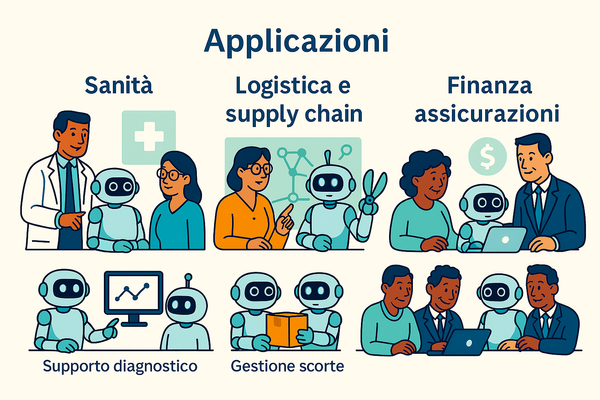
- Veicoli a guida autonoma: Sensori e modelli di machine learning analizzano in tempo reale l’ambiente circostante, prendendo decisioni sicure per la guida.
- Robotica industriale: Robot che ottimizzano processi produttivi, migliorando efficienza e flessibilità.
- Agenti di supporto personalizzato: Che combinano LLM e dati contestuali per offrire assistenza mirata agli utenti.
Conclusioni
Il viaggio del machine learning, dalle idee pionieristiche di Turing agli sviluppi moderni delle reti neurali e degli agenti autonomi, racconta una storia di continua innovazione e di superamento di limiti apparentemente insormontabili. Tuttavia, il campo non rappresenta solo un insieme di successi tecnici, ma un punto di svolta cruciale nel rapporto tra tecnologia e umanità.
Le tecnologie avanzate, come le reti convoluzionali e i modelli generativi, hanno già trasformato profondamente settori come la medicina, l’industria e l’intrattenimento.
Tuttavia, pongono domande urgenti: chi potrà realmente accedere a questi strumenti? E a quali condizioni? La vera accessibilità non si limita al costo contenuto di un servizio, ma implica la libertà di scelta e di cambiamento: strumenti alternativi devono essere disponibili e interoperabili per evitare che pochi monopolizzino l’innovazione. Solo così il machine learning potrà diventare un catalizzatore per ridurre le disuguaglianze globali e portare benefici anche a comunità spesso escluse dal progresso tecnologico.
Un’altra questione centrale è quella della proprietà dei dati, il cuore pulsante del machine learning. I sistemi avanzati si basano su enormi quantità di dati, spesso raccolti senza piena consapevolezza degli utenti. Questo apre interrogativi fondamentali: chi possiede i dati? Chi controlla il loro utilizzo? Come possiamo garantire che vengano gestiti in modo equo, trasparente e rispettoso della privacy? Senza una regolamentazione chiara e globale, il rischio è che i dati diventino un privilegio di pochi, alimentando disuguaglianze anziché ridurle.
Il futuro del machine learning non si misura solo nelle sue capacità tecniche, ma nella sua capacità di promuovere un progresso inclusivo, sostenibile e rispettoso dei diritti umani. La sfida non è solo costruire sistemi più potenti, ma garantire che essi siano al servizio di tutti, rispettando valori come la libertà, la privacy e la giustizia sociale. È solo abbracciando un approccio etico e responsabile che il machine learning potrà davvero ridefinire in positivo il nostro rapporto con la tecnologia e con noi stessi.